





RAG vs Fine-Tuning: The Enterprise Decision Framework for 2026
RAG
vs Fine-Tuning: The Enterprise Decision Framework for 2026
Most AI teams get this wrong because they frame it as an either-or
choice. It’s not. RAG and fine-tuning solve fundamentally different
problems, and picking the wrong one (or worse, using one to do the
other’s job) burns months and six figures before anyone notices.
Here’s the decision that actually matters in 2026: your data
dynamics, compliance exposure, latency budget, and request volume should
drive this call — not what’s trending on LinkedIn.
This framework gives you the structured decision logic, real cost
benchmarks, failure modes, and hybrid architecture patterns to make the
right choice for your enterprise. No theory. No hand-waving. Just the
operational math.
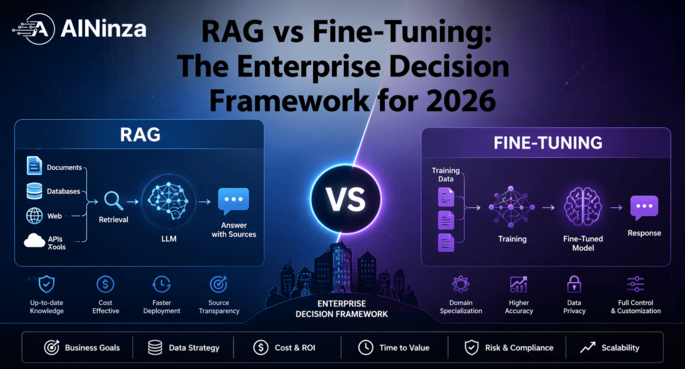
What
RAG and Fine-Tuning Actually Do (The One-Line Version)
Before we get into frameworks, nail this distinction. Neontri’s 2026
enterprise analysis phrases it perfectly: “behavior in
weights, knowledge in context.”
RAG (Retrieval-Augmented Generation) changes
what your model knows right now. It fetches relevant documents
at query time and injects them into the prompt. The model’s weights
don’t change — it just gets better context to work with.
Fine-tuning changes how your model behaves.
You retrain (or partially retrain) the model on your data so it
internalizes patterns, formatting rules, domain-specific language, and
task structures into its weights.
One handles dynamic knowledge. The other handles learned behavior.
Confusion happens when teams try to make one do the other’s job — and
that’s where most enterprise AI projects start bleeding money.
The Decision
Matrix: When Each Approach Wins
Here’s the comparison that matters for enterprise architecture
decisions. Every number here comes from production deployments, not
vendor demos.
| Dimension | RAG | Fine-Tuning |
|---|---|---|
| What it changes | How the model accesses knowledge | How the model behaves |
| Data freshness | Real-time (re-index and go) | Snapshot at training time |
| Setup cost | Under $10K for basic systems | $5K–$50K+ depending on scope |
| Per-request cost | Higher (retrieval + longer prompts) | Lower (no retrieval step) |
| Latency | 100ms–2s overhead from retrieval | Sub-50ms possible |
| Hallucination reduction | 42–90% reduction vs. base models | Does not inherently reduce hallucinations |
| Data deletion compliance | Delete from index, done | May require full retraining |
| Team skills needed | Backend/data engineering | ML training, evaluation, MLOps |
| Best for | Dynamic knowledge, citations, multi-department use | Stable tasks, rigid formatting, high-volume classification |
Sources: Red Hat’s
RAG overview, IBM’s
comparison guide, AlphaCorp’s
2026 cost framework
The pattern is clear: RAG is the default for most enterprise
deployments. Fine-tuning is the scalpel you add when a
specific, measurable gap demands it.
The Data
Freshness Test: Your First Decision Gate
This is the clearest filter, and it resolves most decisions before
you even look at cost.
If your business truth changes daily or weekly —
pricing, inventory, policy documents, regulatory guidance, internal SOPs
— fine-tuning is the wrong tool. Every update means data prep, training,
evaluation, approval, and redeployment. That cycle takes days to weeks.
Meanwhile, your users are getting answers based on last month’s
policies.
RAG handles this cleanly. New policy document? Chunk it, embed it,
it’s live. Employee leaves and you need to purge their data? Delete from
the vector index. Try doing that with knowledge baked into model weights
— your GDPR compliance officer will love that conversation.
Oracle’s
AI comparison guide frames this as the difference between
runtime complexity (RAG) and training
complexity (fine-tuning). That framing still holds in 2026.
Quick test: If more than 10% of your knowledge base
changes monthly, RAG is your default architecture. Full stop.
The Real Cost
Numbers: Not the Blog Slogans
The “RAG is cheap, fine-tuning is expensive” narrative is outdated.
The truth depends entirely on your request volume, and the crossover
point matters more than any upfront number.
Upfront Investment
According to AI Cost
Check’s 2026 RAG cost guide, embedding a 10 million token document
corpus with Gemini Embedding 2 costs about $2.00. A 50
million token corpus? $10.00. That’s the ingestion
cost. It’s essentially a rounding error.
On the fine-tuning side, AI Cost
Check’s fine-tuning analysis puts training costs at:
- Together AI (Llama 3.1 8B): $0.48/million training
tokens — a 100K token dataset over 3 epochs costs under $0.15 - Google Vertex (Gemini 2.0 Flash): $3.00/million
training tokens - OpenAI (GPT-4o): $25.00/million training tokens — a
5,000-example dataset costs ~$187.50
The expensive part of fine-tuning isn’t the training run — it’s
everything around it. Dataset curation alone can eat 20–40 hours of
senior engineer time. At $75/hour, that’s $1,500–$3,000 before you even
start a training job.
Runtime Economics: Where
It Gets Real
Here’s where most teams miscalculate. RAG adds token cost to every
single request because retrieved context inflates the prompt.
Production benchmarks from AlphaCorp’s
2026 framework show per-1K-query costs:
| Configuration | Cost per 1K Queries |
|---|---|
| Base model alone | $11 |
| Fine-tuned model | $20 |
| Base + RAG | $41 |
| Fine-tuned + RAG | $49 |
That retrieval tax compounds. Adding 2,000 tokens of context at $2.50
per million input tokens costs $0.005 per request. At 1 million
requests/month? $5,000 just for the retrieval overhead.
At 10 million requests? You’re looking at $50,000+ monthly.
The Crossover Point
Under 100K requests/month: RAG is almost always
cheaper and faster to launch. The overhead stays manageable.
100K–500K requests/month: Start modeling carefully.
If tasks are repetitive and structurally stable, fine-tuning a small
model starts competing.
500K+ requests/month with stable tasks: Fine-tuned
small models win on unit economics. The per-request savings compound
into real money.
AI Cost Check estimates that at 10,000 requests/day, the inference
cost difference between a fine-tuned Llama 3.1 8B ($0.90/day) and a
fine-tuned GPT-4o ($56.30/day) adds up to $20,221 per
year. Model choice matters more than architecture choice at
high volume.
Compliance and
Governance: RAG’s Strongest Card
For regulated enterprises, this dimension often matters more than
cost — and it’s where RAG has its most decisive advantage.
The EU AI Act deadline for high-risk systems hits
August 2, 2026. Neontri’s
enterprise analysis explicitly connects architectural choice to
compliance readiness:
- RAG lets you purge indexed data instantly, enforce
document-level access controls, and maintain clear data lineage. Subject
access requests under GDPR? Delete from the index, reindex, done. - Fine-tuning bakes data into model weights. Removing
that influence is technically murky and may require full retraining — a
process that’s hard to audit and harder to prove complete.
AWS’s
prescriptive guidance reinforces this with detailed requirements
around governance, retention policies, RBAC, identity integration, and
regional routing for GDPR and HIPAA compliance.
The caveat: RAG isn’t automatically compliant. A
poorly governed RAG system can still expose sensitive data or violate
access boundaries. The architecture creates the opportunity for
better governance. You still have to build it right — with chunk-level
access controls, audit logging, and proper data lineage.
Latency: The
Hard Constraint Nobody Wants to Hear
If your SLA requires sub-50ms responses, RAG probably can’t help you.
Period.
Retrieval adds 50–200ms of overhead according to
Neontri’s benchmarks. The full chain includes query embedding, vector
search, reranking, prompt assembly, and generation over a longer
context. Even with optimized vector databases offering sub-millisecond
search, the end-to-end chain still carries meaningful latency.
Where fine-tuning wins on latency: – Edge
deployments with no network round-trip – Trading systems and real-time
financial applications – Industrial control systems with hard timing
constraints – High-frequency classification (ticket routing, content
moderation)
Where RAG latency is fine: – Conversational
enterprise assistants (200–500ms acceptable) – Internal knowledge search
(users expect search-engine timing) – Customer support bots (sub-2s is
standard)
Know your latency budget before you pick your architecture. This
constraint eliminates options faster than any cost analysis.
The
Hybrid Architecture: What Winning Teams Actually Build
Here’s the thing about the RAG vs. fine-tuning debate: the
best production systems in 2026 aren’t choosing. They’re
combining.
Consider a customer-facing financial advisor chatbot: – It needs
today’s portfolio values and market data → that’s RAG –
It needs to maintain an approved professional tone and include
legal disclaimers in every response → that’s fine-tuning
Neither approach alone covers both requirements. And trying to force
one approach to handle both is where enterprise projects go off the
rails.
RAFT: The Structured Hybrid
Retrieval-Augmented Fine-Tuning (RAFT) is gaining
serious traction in production systems. As detailed in Alapan
Sur’s analysis on Medium, RAFT trains the model specifically to work
well with retrieved context — teaching it to extract relevant
information from noisy retrieval results rather than just generating
from whatever it’s given.
Oracle’s
implementation guide notes that after organizations invest in
fine-tuning, RAG often becomes a natural addition. The reverse also
holds — teams running RAG pipelines eventually find formatting and
behavioral gaps that fine-tuning closes.
The Practical Hybrid Stack
Here’s what a production hybrid architecture looks like:
- RAG layer handles dynamic knowledge retrieval,
citations, and data freshness - Fine-tuned base model enforces output structure,
domain language, and brand voice - Router layer decides which queries need full RAG
retrieval vs. direct model response - Tiered model selection uses cheap models for simple
queries, premium models for complex synthesis
This isn’t theoretical — it’s the architecture pattern that AWS
recommends in their prescriptive guidance for enterprises scaling
LLM deployments.
Who Should Use What:
The Decision Flowchart
Choose RAG if:
- Your knowledge base changes weekly or more frequently
- You operate under GDPR, HIPAA, or EU AI Act obligations with
deletion requirements - You need source citations and audit trails in responses
- You’re building a cross-departmental assistant (HR, legal, sales,
IT) on shared infrastructure - Your team has strong backend engineering but limited ML training
experience - Your request volume is under 500K/month and latency requirements are
relaxed
Choose fine-tuning if:
- Your task is narrow, stable, and structurally rigid (ticket
classification, invoice extraction, structured reports) - You’re processing millions of repetitive requests monthly and unit
economics matter - You need sub-50ms latency or edge deployment
- You have 500+ high-quality labeled examples and a clear evaluation
framework - Your team includes ML engineers who can manage training pipelines
and drift monitoring
Go hybrid if:
- Your system needs both current facts and controlled behavior
- You’re building a customer-facing product where trust, accuracy, and
brand consistency all matter - Your organization has the operational maturity to manage both
retrieval infrastructure and model training - Quality gaps in either approach alone are measurable and
documented
Reconsider your approach
entirely if:
- You don’t have clear success metrics — don’t fine-tune without
knowing what “better” means - Your training data is noisy or poorly labeled — fine-tuning on bad
data increases hallucinations - You’re treating RAG as a prompt trick rather than production
infrastructure
The 90-Day Implementation
Roadmap
Here’s how this actually plays out in practice:
Days 1–30: Start with RAG
- Deploy a basic RAG pipeline on your highest-value knowledge
base - Use a mid-tier model (GPT-4.1 mini or Gemini 2.5 Flash) as your
generator - Measure: answer quality, retrieval relevance, latency, cost per
query - Establish baselines before changing anything
Days 31–60: Optimize
the Retrieval Pipeline
- Tune chunking strategy (most teams start with chunks that are too
large) - Add reranking if retrieval precision is below 80%
- Implement caching for frequently asked questions
- Monitor: which queries fail repeatedly? Where does RAG fall
short?
Days 61–90: Add
Fine-Tuning Where Gaps Exist
- Identify specific, measurable quality gaps that RAG can’t close
- Collect 500–1,000 high-quality examples from production logs
- Fine-tune a small model (8B parameter) for the specific failing
task - A/B test fine-tuned model against RAG-only baseline
- Deploy only if improvement is statistically significant
This phased approach costs 60–80% less than trying to build a hybrid
system from day one, and it produces better results because each
decision is informed by real production data.
Field
Reality: What Actually Fails in Enterprise Deployments
Here’s what nobody puts in the vendor pitch deck. The biggest mistake
teams make isn’t choosing RAG vs. fine-tuning — it’s fine-tuning
to solve what is actually a retrieval problem. A team notices
outdated or irrelevant responses and assumes the model needs retraining.
But the real issue is that their chunking strategy breaks semantic
meaning, their retrieval pipeline pulls irrelevant chunks, or they have
no reranking step. Fix the retrieval, and the “model quality” problem
often disappears overnight. We’ve seen this pattern at Aeologic across
healthcare, logistics, and financial services clients — teams burning
$30K–$50K on fine-tuning cycles when a $2K retrieval pipeline overhaul
would have solved the problem.
The second pattern that kills deployments: assuming RAG stays
cheap at scale. Teams build a proof of concept with 100
queries/day and extrapolate the cost linearly. But production traffic is
10,000+ queries/day, context windows grow as features expand, and
suddenly the monthly bill is 50x the forecast. AI Cost
Check documents this phenomenon in detail — the support bot that
costs $37/month on Mistral Small becomes $1,800/month on Claude Sonnet
because nobody designed a tiered model routing strategy. Budget for 10x
your POC volume from day one, or you’ll be explaining a cost overrun to
the CFO within 90 days.
Cost
Optimization Playbook: Cutting Your Bill by 40–60%
Whether you choose RAG, fine-tuning, or hybrid, these optimizations
apply:
For RAG Systems
- Retrieve fewer, better chunks. If your median
question is answered with 3 chunks, don’t retrieve 8. Every extra 1,000
input tokens adds cost forever. - Implement tiered model routing. Use a $0.0005/query
model (Mistral Small) for FAQ-level questions. Reserve $0.025/query
models (Claude Sonnet) for complex synthesis. - Cache aggressively. If your users ask the same 500
questions repeatedly, cache the answers. This alone can cut costs by
30–50%. - Trim system prompts. RAG stacks often carry bloated
system prompts that inflate every single request. Move static logic to
application code.
For Fine-Tuning
- Use LoRA instead of full fine-tuning.
Parameter-efficient methods reduce compute costs by 50–80% with minimal
quality loss. - Start with the smallest effective model. If a
fine-tuned 8B model handles your task, don’t fine-tune a 70B model. - Budget for 3–5 iterations. Your first fine-tune
rarely ships. Each iteration costs another training run. - Leverage synthetic data. Use a larger model to
generate initial training examples, then have humans review. Cuts
curation time by 50–70%.
For Hybrid Systems
- Route explicitly. Don’t send every query through
the full hybrid pipeline. Build a classifier that decides which path
each query takes. - Monitor cost per query type. Some queries cost 10x
more than others. Know which ones and optimize the expensive paths. - Reuse retrieval across sessions. If a user asks
multiple questions about the same document set, cache the retrieval
results.
Enterprise
RAG Architecture: What a Production Stack Looks Like
For teams ready to build, here’s the reference architecture:
┌─────────────────────────────────────────────────────┐
│ User Query │
├─────────────────────────────────────────────────────┤
│ Query Router (classification + intent detection) │
├──────────────┬──────────────┬───────────────────────┤
│ Simple Path │ RAG Path │ Hybrid Path │
│ (cached / │ (retrieval │ (fine-tuned model │
│ FAQ) │ + gen) │ + RAG context) │
├──────────────┴──────────────┴───────────────────────┤
│ Vector DB + Reranker + Access Control Layer │
├─────────────────────────────────────────────────────┤
│ Document Ingestion Pipeline (chunking, embedding) │
├─────────────────────────────────────────────────────┤
│ Audit Log + Cost Monitor + Drift Detection │
└─────────────────────────────────────────────────────┘Each layer has its own cost profile, scaling characteristics, and
failure modes. The key insight: the router layer is the most
important component because it determines which expensive paths
get exercised and how often.
Frequently Asked Questions
Should
we start with RAG or fine-tuning for our first enterprise AI
project?
Start with RAG. For 80–90% of enterprise use cases in 2026, RAG is
the safer, more flexible, and more governable default. It handles
changing data, supports compliance requirements, scales across
departments, and doesn’t require your team to become ML training
specialists. Add fine-tuning later only when you can point to a
specific, measurable gap that RAG alone can’t close.
How
much does a production RAG system actually cost per month?
It depends heavily on model choice and query volume. An internal
knowledge assistant handling 15,000 queries/month costs as little as
$8/month on Mistral Small 3.2 or up to $383/month on Claude Sonnet 4.6,
per AI
Cost Check’s 2026 benchmarks. A customer-facing bot at 60,000
queries/month ranges from $37 to $1,800. The generation model — not the
vector database — is your primary cost lever.
What’s
the break-even point for fine-tuning vs. prompt engineering?
The crossover is typically 50,000–500,000 requests, per AI Cost
Check’s analysis. Below 50K monthly requests, prompt engineering
with caching is almost certainly more cost-effective. Above 500K with
stable, repetitive tasks, fine-tuning saves real money by eliminating
lengthy system prompts and few-shot examples from every request.
Can
RAG and fine-tuning work together in the same system?
Absolutely — and they should for high-stakes systems. The hybrid
approach (sometimes called RAFT when formalized) uses fine-tuning for
behavioral consistency and output structure while RAG handles dynamic
knowledge and citations. AWS’s
prescriptive guidance recommends this pattern for enterprises
scaling LLM deployments.
How
do we handle compliance (GDPR, EU AI Act) with each approach?
RAG has a clear advantage. You can purge data from vector indexes
instantly, enforce document-level access controls, and maintain data
lineage. Fine-tuning bakes data into model weights, making deletion
requests technically complex and potentially requiring full retraining.
With the EU AI Act deadline for high-risk systems on August 2, 2026,
architecture choice has direct regulatory implications.
What’s
the most common mistake enterprises make when choosing between RAG and
fine-tuning?
Fine-tuning to solve a retrieval problem. Teams see poor answer
quality and assume they need to retrain the model, when the real issue
is chunking strategy, retrieval relevance, or missing reranking. Fixing
the retrieval pipeline is typically 10x cheaper and faster than a
fine-tuning cycle.
References
- AlphaCorp AI — RAG
vs. Fine-Tuning in 2026: A Decision Framework With Real Cost
Comparisons (March 2026) - AI Cost Check — RAG Costs in
2026: What Retrieval-Augmented Generation Actually Costs (April
2026) - AI Cost Check — AI
Fine-Tuning Costs in 2026: Training, Inference, and ROI Compared
(March 2026) - Red Hat — RAG vs
Fine-Tuning: Key Differences - IBM — RAG vs
Fine-Tuning - Oracle — RAG
vs Fine-Tuning for AI - AWS — Tailoring
Foundation Models: RAG, Fine-Tuning, and Hybrid Approaches - Neontri — RAG and
Fine-Tuning for Enterprise AI (2026) - StackAI — RAG
vs Fine-Tuning for Enterprise AI (February 2026) - Alapan Sur / Medium — RAFT:
When RAG Meets Fine-Tuning (February 2026)
AINinza is powered by Aeologic
Technologies — an enterprise AI consulting firm that helps
organizations design, build, and scale production AI systems. Whether
you’re evaluating RAG vs. fine-tuning, building hybrid architectures, or
optimizing existing deployments, our team brings hands-on implementation
experience across healthcare, logistics, financial services, and
operations. Start a conversation
→





